
🤦🏻♂️ 들어가기에 앞서..
우리가 앞에 포스팅에서 봤던 BERT 모델은, Encoder 모델입니다. Encoder 모델은 각 단어에 대한 어텐션 연산을 수행하면서 문장의 의미를 파악하죠. Encoder 모델의 반대는 Decoder 모델인데, GPT같은 모델이 예시입니다. Decoder 모델은, 지금까지 생성한 문장을 바탕으로 이후의 문장을 생성하죠. 혹시 여기서 두 모델의 차이가 느껴지시나요? Encoder 모델을 양방향 인코딩을 진행합니다. 하나의 단어에 대해서 앞에 등장하는 단어, 뒤에 등장하는 단어와의 관계를 연산하죠. 하지만 Decoder 모델은 단방향 인코딩을 진행합니다. 과거에 생성했던 단어들을 바탕으로 앞으로의 단어를 예측하기 때문입니다. 일단 Encoder 모델과 Decoder 모델의 차이점은 이정도만 알고 계시면 될 것 같습니다.
🧩 트랜스포머란?
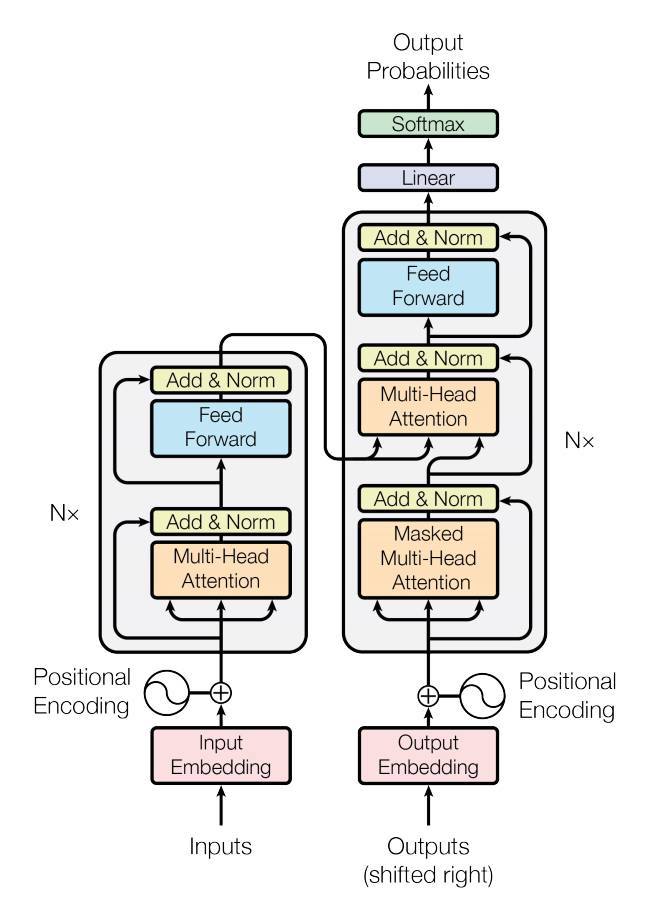
TIP위의 모델은 트랜스포머 모델입니다. 현재 LLM을 비롯한 자연어 처리 뿐만 아니라, 컴퓨터 비전쪽에서도 사용되고 있는 모델입니다. 이 모델은 Attention is all you Need에서 제안된 모델로 나중에 이 논문을 분석하겠지만 일단은 트랜스포머라는게 현재 인공지능에 중요한 개념으로 다뤄지고 있다 정도로만 생각하는게 좋습니다. 왼쪽 부분이 Encoder 모델이고 오른쪽 부분이 Decoder 모델입니다.
⏰ Encoder 모델의 특성
- Encoder 기본 블럭의 구성
- Multi-Head Attention: Self-Attention이 여러번 수행됨
- Add & Norm: 잔차 연결(Residual Connection)과 정규화(Normalization)를 의미함
- Feed-Forward: 완전 연결 신경망(Fully Connected Layer)을 의미함
CAUTION그림에서는 하나의 Encoder 블록이 그려져있지만, 실제로는 Encoder 블록이 스택처럼 여러개 적층되어있는 구조입니다. 각 Encoder 블록을 거치면서 각 단어의 의미를 더 잘 파악할 수 있게 되죠. 일반적으로 BERT 모델의 경우 8개의 인코더 층으로 이루어져있습니다.
추가 설명: 잔차 연결은 자연어 처리나 컴퓨터 비전 파트에서 중요한 개념인데요, 입력에 대해서 활성화 함수를 거친 신호만 다음으로 전달하는 것이 아닌 활성화 함수를 거친 신호와 활성화 함수를 거치기 전의 신호의 합을 진행한 뒤 다음으로 전달하는 것을 의미합니다. 기존의 정보의 소실되는 것을 줄일 수 있습니다.
🔋 위치 임베딩의 과정
자연어를 처리하는데 있어서 단어의 위치가 중요할까요? 중요하다면 왜 그럴까요? 만약 There is a prince와 Is there a prince 문장이 있다고 합시다. 이 두 문장이 같은 문장인가요? 하나는 평문이고 하나는 의문문의 구성이죠. 저곳에 왕자가 있다와, 저곳에 왕자가 있는가는 다른 문장이죠. 여기까지 본다면 문장에서 각 단어의 위치는 굉장히 중요한 요소로 보입니다.
과거의 자연어 처리에서, 새로운 문장을 생성하는 경우 RNN(Recurrent Neural Network, RNN)을 사용하거나, LSTM(Long-Short Term Memory, LSTM)를 사용했습니다. RNN의 경우 순환 신경망 구조로, 데이터가 일렬로 위치합니다. 따라서 단어의 위치 정보가 들어가있죠. 하지만 문장이 길어질수록, 처음에 있던 정보가 점점 사라지는 장기 의존성 문제(Long-Term Dependencies)가 발생하기 시작합니다. 이를 해결하기 위해서 LSTM이 도입되기 시작했고 LSTM은 연산을 병렬적으로 처리할 수 있다는 장점으로 많은 인기를 받았습니다. 지금도 시계열 데이터를 예측하는 부분에서는 여전히 LSTM이 중요한 도구로 사용됩니다. 하지만 LSTM은 각 단어에 대한 계산을 병렬적으로 처리하기 때문에 당연하게도 위치 정보가 소실될 수 밖에 없었습니다.
이 때, 트랜스포머 모델이 등장했고, 트랜스포머 모델도 병렬로 어텐션 연산을 수행하기 때문에 위치 정보가 소실되었죠. 이를 해결하고자 문장을 임베딩화 한 이후에, 위치 임베딩 값을 더하여 위치 정보를 넣기 시작했습니다.
WARNING여기서부터는, 수학적인 개념이 등장합니다. 비전공자에게는 호흡곤란 및 충격을 줄 수 있으니 주의해주세요. :)
🧯 Self-Attention 과정
우리는 위치 임베딩을 통해서, 기존 임베딩 값에 위치값을 추가했습니다. 이제 우리는 대망의 어텐션 연산을 수행해야합니다. 어텐션 연산이란 무엇일까요?
IMPORTANT
⌛️ Attention 수식의 모든 것
- : Attention Value로 우리가 구하고자하는 Attention 값을 의미함
- : 모든 확률의 합이 1이 되도록 만들어주는 함수
- (Query): Query는 우리가 찾을 단어
- (Key): Key는 우리가 찾는 단어
- (Value): Value는 우리가 찾는 단어의 내용
- : 임베딩 차원 수
이해합니다. 이게 뭔소리인지 모르겠죠. 저 역시 처음 공부할 때 그랬습니다. 이게 무슨 🐕소리인지 했죠. 제가 정말 쉽게 정리해드리겠습니다.
TIP자, 우리는 임베딩 벡터와 임의의 가중치 , , 를 점곱(dot-product)을 해서 Query, Key, Value를 얻습니다. 여기서 Query, Key, Value가 뭘까요?
우리가 도서관에 갔습니다. 도서관에는 엄청 많은 책이 있겠죠? 저는 여기서 차라투스트라는 이렇게 말했다라는 책을 찾을 겁니다. 여기서 제가 찾고자하는 책을 Query라고 합니다. 여기서 Query는 차라투스트라는 이렇게 말했다가 되겠죠? 이제 도서검색대 앞으로 와서 검색창에 차라투스트라는 이렇게 말했다를 치고, 위치가 있는 곳까지 이동합니다. 철학부분 선반에 차라투스트라는 이렇게 말했다 책이 보이네요. 지금 보이는 저 책의 제목이 바로 Key입니다. 마지막으로 책을 집어들고 차라투스트라는 이렇게 말했다의 책 내용을 확인합니다. 여기서의 책 내용을 Value라고 하는거죠.
다 이해하셨나요? 여기서 제가 공부할 때, 궁금했던게 두 가지가 있었습니다.
- 는 왜 해야하는가?
- 와 의 점곱이 너무 커지지 않게 하기 위해서 정규화를 시킨다고 이해하시면 됩니다. 이는 분산이 커지지 않게 하기 위함입니다.
- 와 를 점곱하는데, 를 Transpose한다고 해서 의미가 변하지 않는가?
- 네. 의 값은 Transpose를 진행하더라도 그 의미가 변형되지는 않습니다. Transpose를 하는 이유는 오직, 연산을 하기 위해서죠.
📡 Multi-Head Attention은 그러면?
이름에서 볼 수 있듯이 Multi-Head Attention은 Self-Attention을 N번 하는 과정입니다. 각 과정은 병렬로 처리되고 일반적으로 이 N을 Head라고 합니다. 일반적으로 BERT에서는 Head를 12로 지정합니다.
여기서 굳이 Head로 어텐션 연산을 나눠주는 이유가 뭘까요? 그냥 한번에 연산을 하면 편할텐데 말이죠;;;
from transformers import AutoModel, AutoTokenizer
model_ckpt = 'distilbert-base-uncased'model = AutoModel.from_pretrained(model_ckpt)tokenizer = AutoTokenizer.from_pretrained(model_ckpt)input_text = 'I am full'tokenized_text = tokenizer(input_text, return_tensors='pt')outputs = model(**tokenized_text)outputs.last_hidden_state[0].size()# 결과: torch.Size([5, 768])결과를 보면 [CLS], I, am, full, [SEP] 총 5개의 토큰으로 구성될꺼고, 결과에 있는 5는 토큰을 의미하겠군요. DistilBERT 모델을 거치면, 이 5개의 단어가 해당 문장의 문맥을 반영하여 768개의 벡터로 표기됩니다.
자, 여기서는 BERT 모델을 통과한 결과를 나타냈는데요, 실제로는 이 값을 만들기 위해서 바로 Multi-Head Attention 과정을 거친다는 겁니다. 768개의 차원을 12개의 묶음이 되도록 나눈 다음에 각각을 Self-Attention 연산을 수행하고 열 병합(Concatenate)을 진행합니다. 여기서 12개의 묶음 중에서 1번 묶음은 명사와 형용사와의 관계를 계산하고, 2번 묶음은 명사와 서술어와의 관계를 계산하는 등(물론 여기서 1번이 무조건 명사와 형용사와의 관계를 계산하는건 아닙니다. 하나의 예시입니다.) 각 묶음에서 문장 내의 다른 관계들을 계산하는거죠. 이렇게 계산한 결과는 아마 하나의 Self-Attention만 수행하는 것보다 훨씬 풍부한 정보를 갖게 될겁니다.
🛢️ Add & Norm이란?
앞에서 제가 말했듯, Add는 잔차 연결을 의미하고 Norm은 정규화를 의미합니다. 다시 설명을 하자면, 잔차 연결은 정보가 소실되지 않게 활성화함수로 통과된 값과 그렇지 않은 값의 합을 다음층에 넘기는 것을 의미합니다. Norm은 정규화인데, 각 층을 통과할때마다 분포가 계속해서 달라지겠죠? 달라지는 분포는 모델의 학습률을 떨어뜨립니다. 따라서 각 층마다 정규화를 시켜서 학습률을 안정화시키는거죠.
😊 마지막, Feed Forward
이 부분은 DeepL을 한번이라도 접해본 사람은 아마 알텐데, 완전 연결 신경망을 의미합니다.
❤️ 진짜 진짜 마지막.. 단일 어텐션 알고리즘 구현
import torchimport torch.nn as nnimport torch.nn.functional as Fimport numpy as np
embed_layer = nn.Embedding(tokenizer.vocab_size, 768) # 임베딩 레이어position_embed_layer = nn.Embedding(tokenizer.vocab_size, 768) # 위치 레이어
position_ids = torch.arange(5, dtype=torch.long).unsqueeze(0) # [1, 5] 크기position_encoidngs = position_embed_layer(position_ids) # 위치 임베딩token_embeddings = embed_layer(torch.tensor(tokenized_text.input_ids)) # 토큰 임베딩input_embeddings = token_embeddings + position_encoidngs # 입력은 토큰 + 위치 [1, 5, 768]
weight_q = nn.Linear(768, 768)weight_k = nn.Linear(768, 768)weight_v = nn.Linear(768, 768)
querys = weight_q(input_embeddings) # [1, 5, 768]keys = weight_k(input_embeddings) # [1, 5, 768]values = weight_v(input_embeddings) # [1, 5, 768]
def compute_attention(querys, keys, values): dim_k = querys.size(-1) # 768 scores = querys@keys.transpose(1, -1)/np.sqrt(dim_k) weights = F.softmax(scores, dim=-1) return weights @ values
print('계산 결과: {}'.format(compute_attention(querys, keys, values)))"""계산 결과: tensor([[[-0.5023, -0.8920, 0.3748, ..., -0.0538, -0.6716, -0.1786], [-0.0773, -0.6096, -0.2301, ..., -0.0108, -0.8486, -0.3704], [ 0.0708, -0.7029, 0.4168, ..., 0.0377, -0.9079, -0.3822], [-0.2551, -0.6849, -0.3193, ..., -0.0312, -0.6093, -0.4267], [-0.3334, -0.5717, -0.3098, ..., 0.1180, -0.3924, -0.0895]]], grad_fn=<UnsafeViewBackward0>)"""![[NLP] How BERT model operate in python?](/images/test2.png)
![[Paper] Review with ToolOrchestra](/images/test4.png)
![[Paper] Review with StepWiser](/images/test3.png)